
An Image caption generator system implies the detection of the image as well as producing the caption with natural language processing by the computer. This is a tedious job. Image caption generator systems can solve various problems, such as self-driving cars, aiding the blind, etc.
The recent research at the Department of Computer Science and Engineering proposes a model to generate the captions for an image using ResNet and Long Short-Term Memory. Assistant Professors Dr Morampudi Mahesh Kumar and Dr V Dinesh Reddy have published the paper Image Description Generator using Residual Neural Network and Long-Short-Term Memory in the Computer Science Journal of Moldova with an impact factor of 0.43.
The captions or descriptions for an image are generated from an inverse dictionary formed during the model’s training. Automatic image description generation is helpful in various fields like picture cataloguing, blind persons, social media, and various natural language processing applications.
Despite the numerous enhancements in image description generators, there is always a scope for development. Taking advantage of the larger unsupervised data or weakly supervised methods is a challenge to explore in this area, and this is already there among the future plan of the researchers. Another major challenge could be generating summaries or descriptions for short videos. This research work can also be extended to other sets of natural languages apart from English.
Abstract
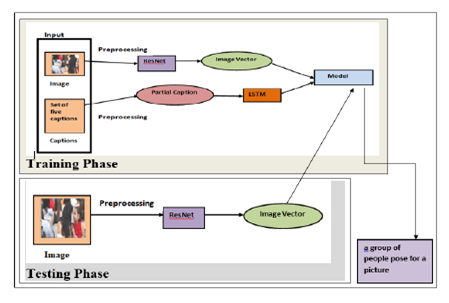 Human beings can describe scenarios and objects in a picture through vision easily, whereas performing the same task with a computer is a complicated one. Generating captions for the objects of an image helps everyone to understand the scenario of the image in a better way. Instinctively describing the content of an image requires the apprehension of computer vision as well as natural language processing. This task has gained huge popularity in the field of technology, and there is a lot of research work being carried out. Recent works have been successful in identifying objects in the image but are facing many challenges in generating captions to the given image accurately by understanding the scenario. To address this challenge, we propose a model to generate the caption for an image. Residual Neural Network (ResNet) is used to extract the features from an image. These features are converted into a vector of size 2048. The caption generation for the image is obtained with Long Short-Term Memory (LSTM). The proposed model was experimented with on the Flickr8K dataset and obtained an accuracy of 88.4%. The experimental results indicate that our model produces appropriate captions compared to the state of art models.
Human beings can describe scenarios and objects in a picture through vision easily, whereas performing the same task with a computer is a complicated one. Generating captions for the objects of an image helps everyone to understand the scenario of the image in a better way. Instinctively describing the content of an image requires the apprehension of computer vision as well as natural language processing. This task has gained huge popularity in the field of technology, and there is a lot of research work being carried out. Recent works have been successful in identifying objects in the image but are facing many challenges in generating captions to the given image accurately by understanding the scenario. To address this challenge, we propose a model to generate the caption for an image. Residual Neural Network (ResNet) is used to extract the features from an image. These features are converted into a vector of size 2048. The caption generation for the image is obtained with Long Short-Term Memory (LSTM). The proposed model was experimented with on the Flickr8K dataset and obtained an accuracy of 88.4%. The experimental results indicate that our model produces appropriate captions compared to the state of art models.