School of Engineering and Sciences
Department of Computer Science and Engineering

 In a significant contribution to the intersection of technology and healthcare, Dr V M Manikandan, Assistant Professor in the Department of Computer Science and Engineering along with a team of dedicated undergraduate students, has co-authored a pivotal book chapter. The chapter, titled “Advancements and Challenges of Using Natural Language Processing in the Healthcare Sector,” has been published in the insightful book “Digital Transformation in Healthcare 5.0.”
In a significant contribution to the intersection of technology and healthcare, Dr V M Manikandan, Assistant Professor in the Department of Computer Science and Engineering along with a team of dedicated undergraduate students, has co-authored a pivotal book chapter. The chapter, titled “Advancements and Challenges of Using Natural Language Processing in the Healthcare Sector,” has been published in the insightful book “Digital Transformation in Healthcare 5.0.”
The collaborative effort by Dr Manikandan, Mr Shasank Kamineni, Ms Meghana Tummala, Ms Sai Yasheswini Kandimalla, and Mr Tejodbhav Koduru delves into the innovative applications and potential hurdles of implementing natural language processing (NLP) technologies in healthcare. Their work highlights the transformative power of NLP in analysing vast amounts of unstructured clinical data, thereby enhancing patient care and medical research.
This academic achievement showcases the expertise and commitment of the faculty and students and underscores the institution’s role in driving forward the digital revolution in healthcare. The chapter is expected to serve as a valuable resource for researchers, practitioners, and policymakers interested in developing smarter, more efficient healthcare systems.
Introduction of the Book Chapter
“Digital Transformation in Healthcare 5.0: IoT, AI, and Digital Twin” delves into how advanced technologies like IoT, AI, and digital twins are reshaping healthcare. It provides a comprehensive look at the integration challenges and technological advancements aiming to modernise medical practices. The chapter “Advancements and Challenges of Using Natural Language Processing in the Healthcare Sector” specifically explores how NLP processes vast data in healthcare to transform it into actionable insights, enhancing efficiency and patient care while highlighting the implementation challenges of these technologies. This book is crucial for healthcare and technology professionals interested in the future of digitally enhanced healthcare.
Significance of the Book Chapter
The chapter “Advancements and Challenges of Using Natural Language Processing in the Healthcare Sector” is significant because it encapsulates my interest and expertise in harnessing NLP to enhance healthcare operations. It showcases the potential of technology in transforming healthcare data into valuable, actionable insights, directly aligning with my focus on improving patient outcomes through technological innovation.
Continue reading →
The Department of Computer Science and Engineering is proud to announce the acceptance of the book chapter titled, Dielectric Characterization of Ovine Heart Tissues at Terahertz Frequencies via Machine Learning: A Use Case for in-vivo Wireless Nano-Communication in the book, “Edge-Enabled 6G Networking: Foundations, Technologies, and Applications.” The book chapter by Dr Manjula R and her students, Ms NSK Sarayu, Ms N Sai Sruthi, Ms D Samaya, and Mr K Tarun Teja from the department caters to UG/PG and PhD students, educational institutions, and medical healthcare sectors. Dr Manjula’s research doesn’t just underscore the significance of understanding the dielectric properties of heart tissues but also highlights the transformative potential of machine learning in predicting, diagnosing and offering therapeutic interventions equipped with real-time monitoring capabilities. The research also lays the groundwork for future advancements in this field, facilitating the development of more efficient and reliable in-vivo sensing technologies.
Abstract of the Book Chapter:
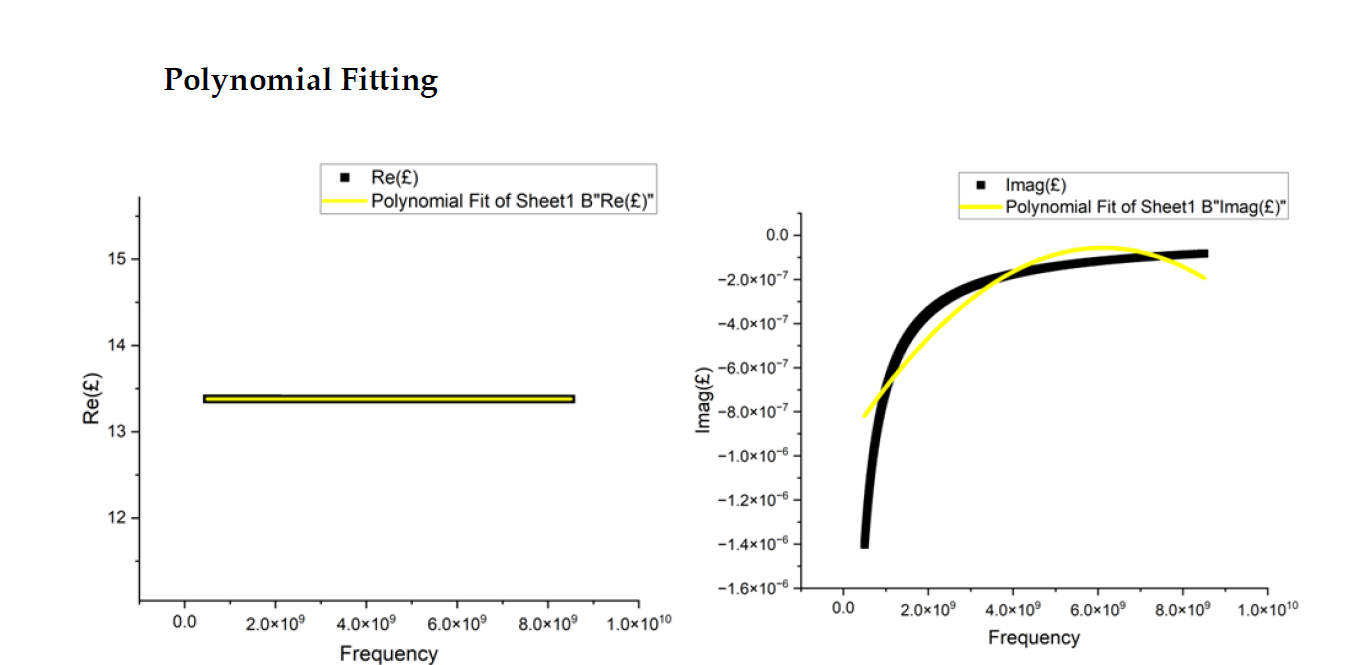
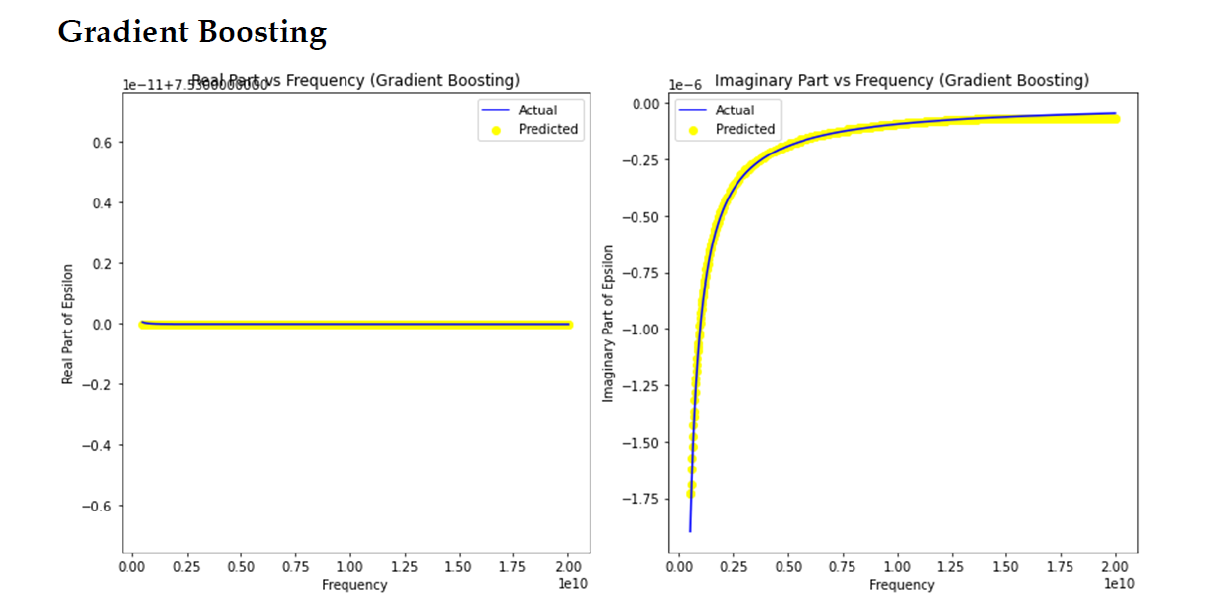
A new generation of sensing, processing, and communicating devices at the size of a few cubic micrometers are made possible by nanotechnology. Such tiny devices will transform healthcare applications and open up new possibilities for in-body settings. A thorough understanding of the in-vivo channel characteristics is essential to achieve efficient communication between the nanonodes floating in the circulatory system (here, it is the heart) and the gateway devices fixed in the skin. This entails one to have accurate knowledge on the dielectric properties (permittivity and conductivity) of cardiac tissues in terahertz band (0.1 to 10 THz). This research examines the strength of the machine learning models in accurate calculation of the dielectric properties of the cardiac tissues. Initially, we generate the data using 3-pole Debye Model and then use machine learning models (Linear Regression, Polynomial Regression, Gradient Boosting, and KNN), on this data, to estimate the dielectric properties. We compare the values predicted by machine learning models with those given by the analytical model. Our investigation shows that the Gradient Boosting method has better prediction performance. Further, we have also validated these results using Origin software employing curve fitting technique. In addition, the research also contributes to the study of data expansion by predicting unknown data based on available experimental data, emphasizing the broader applicability of machine learning in biomedical research. The study’s conclusions enhance areas like non-invasive sensing in the context of 6G, which may improve data and monitoring in a networked healthcare environment.